 泡玩网
泡玩网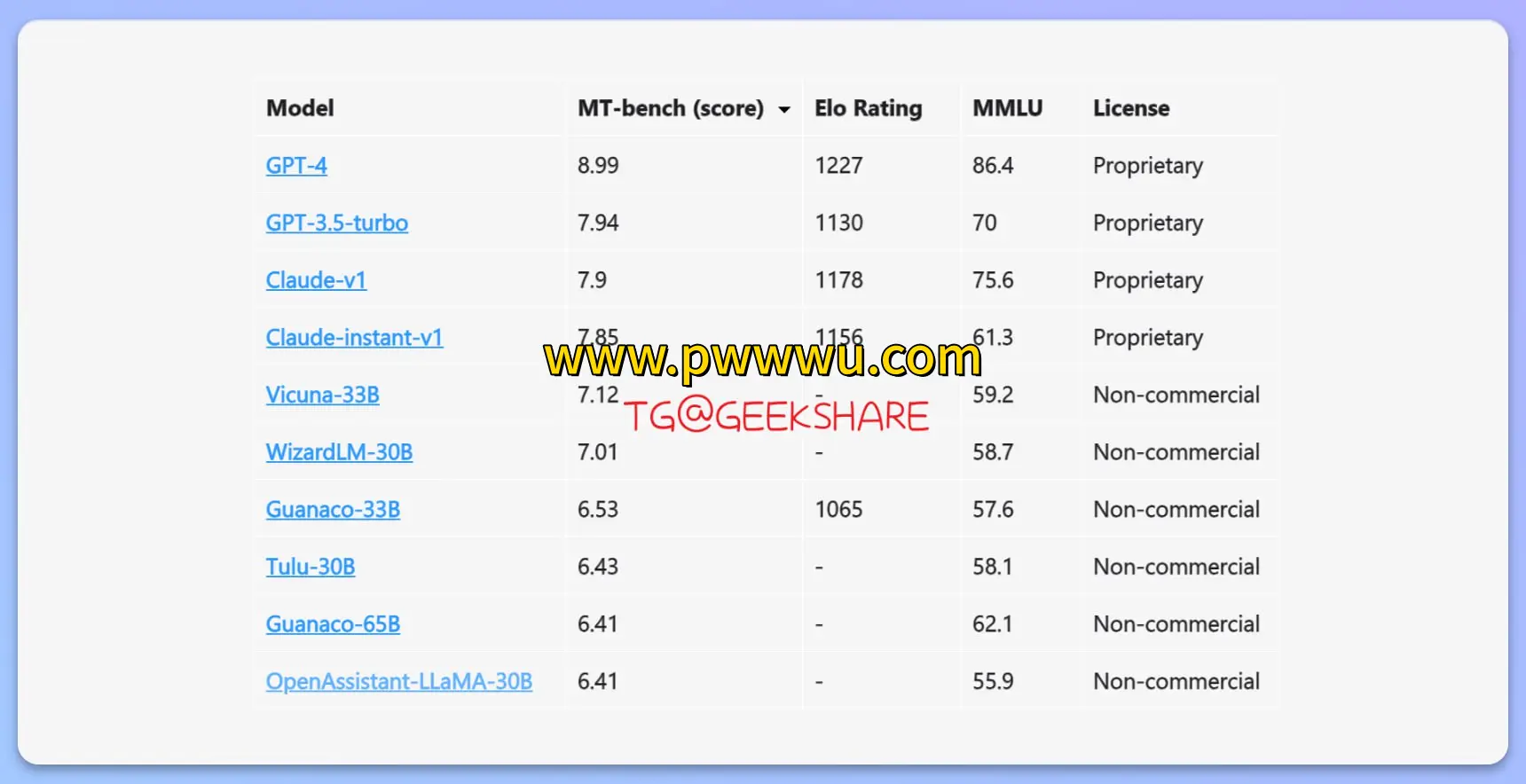
UC伯克利发布语言模型评估榜单:GPT-4持续领跑
在最新公布的全球语言模型能力评测中,来自加州大学伯克利分校的研究团队公布了最新评估结果。本次测评采用名为”MT-bench”的创新评估体系,该测试框架包含80组精心设计的对话式问题,通过多轮交互测试更全面地评估模型的实际表现。
顶尖模型性能对比
测评数据显示,GPT-4依然保持领先地位,展现出卓越的综合能力。紧随其后的是GPT-3.5版本,而Anthropic公司推出的两款Claude系列模型分别位列第三和第四名。值得注意的是,此次采用的评估机制特别注重多轮对话的连贯性与逻辑性,使得测评结果相比以往更具参考价值。
评估体系全面升级
MT-bench评估标准相较于传统测试方法具有显著提升。该体系不仅关注单轮问答的准确性,更重视模型在连续对话中保持上下文关联的能力。每个测试问题都经过专家团队严格筛选,确保能够有效区分不同模型的真实水平。这种创新的评估方式为行业发展提供了新的参考标准,也将推动相关技术向更人性化的交互体验迈进。
分享地址:
https://lmsys.org/blog/2023-06-22-leaderboard/