 泡玩网
泡玩网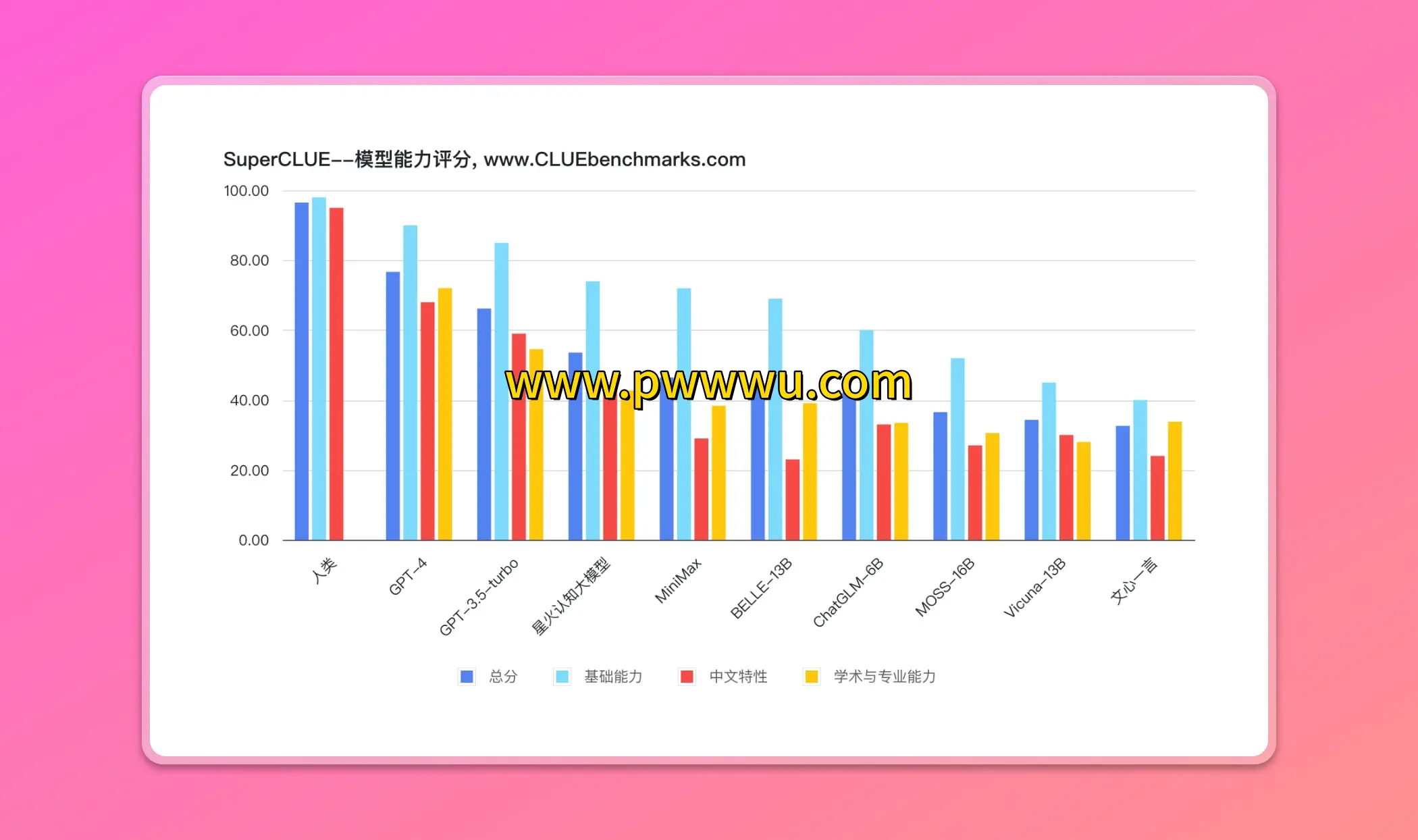
中文通用智能模型评估体系(SuperCLUE)
该测评体系专注于对中文场景下的通用智能模型进行多维度的能力评估
核心观察维度
- 各模型在差异化任务中的表现差异
- 与国际主流模型的能力对标情况
- 模型表现与人类水平的差距分析
值得关注的是,在当前评估体系中,人类智能仍保持着明显优势,尚未有模型能够全面超越人类的综合表现。该测评通过系统化的测试方法,持续追踪中文大模型的发展轨迹,为行业提供客观的参照标准。
分享地址:
https://github.com/CLUEbenchmark/SuperCLUE
该测评体系专注于对中文场景下的通用智能模型进行多维度的能力评估
值得关注的是,在当前评估体系中,人类智能仍保持着明显优势,尚未有模型能够全面超越人类的综合表现。该测评通过系统化的测试方法,持续追踪中文大模型的发展轨迹,为行业提供客观的参照标准。
https://github.com/CLUEbenchmark/SuperCLUE