 泡玩网
泡玩网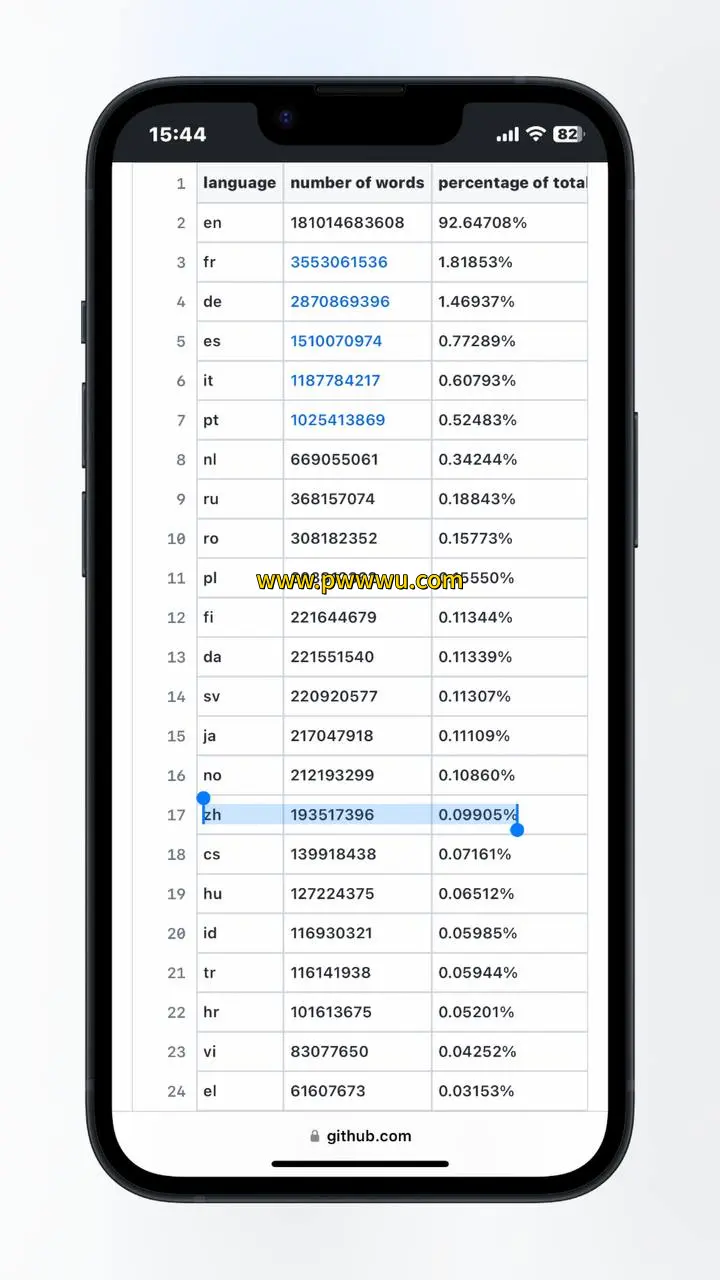
简介
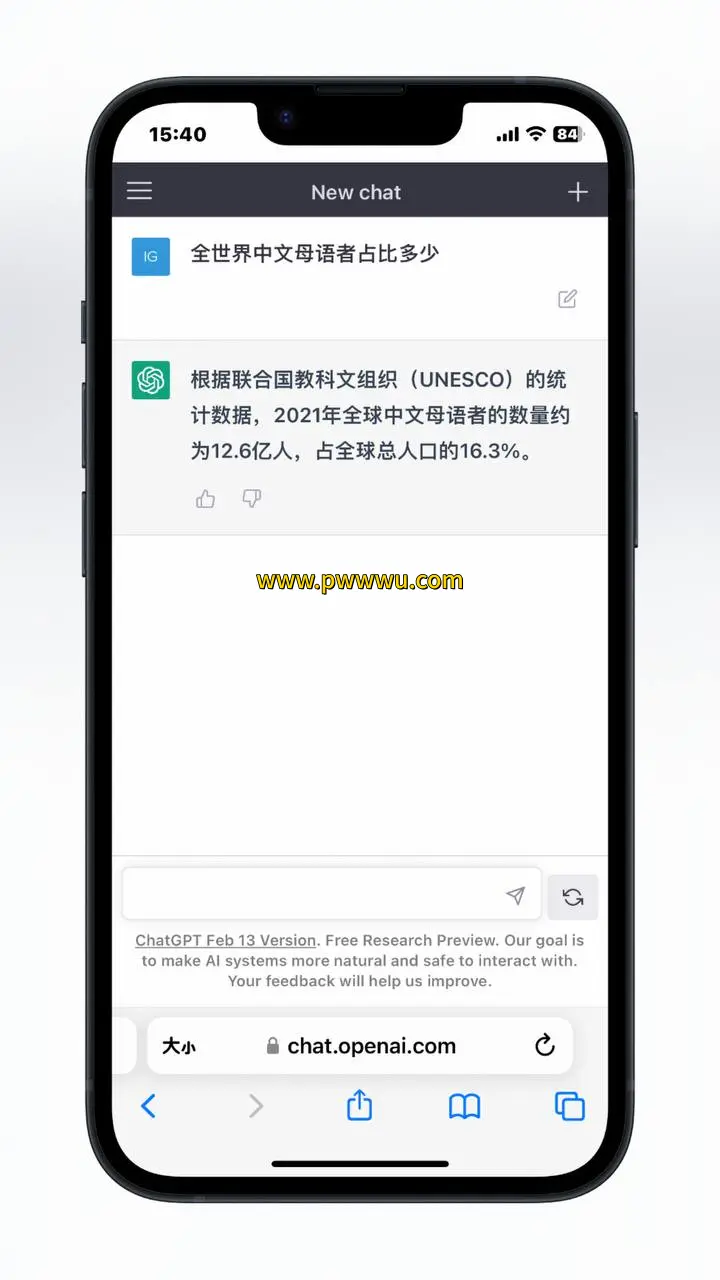
基于GPT-3模型训练过程中采用的语言资料统计表明,其涉及简体中文的文本数量仅占整体数据规模的0.09905%。与此同时,根据智能对话系统披露的信息,2021年全球以中文为母语的人口数量约达12.6亿,这个数字相当于全世界人口总量的16.3%。
语言资源分布特征
现有数据显示,虽然中文使用者在全球人口中占据显著比例,但在人工智能训练资料库中,中文内容的占比仍处于较低水平。这种现象反映出当前语言资源分布存在不均衡状况,也提示我们需要关注训练数据对不同语言群体的覆盖程度。
语言影响力分析
从数据对比可以看出,中文使用群体的规模与人工智能训练资料中中文内容的比重形成鲜明对照。这种情况可能对模型在处理中文信息时的表现产生一定影响,同时也为改进多语言模型提供了有价值的参考依据。
分享地址:
https://github.com/openai/gpt-3/tree/master/dataset_statistics